

LM大模型标准api使用教程
前言
在ChatGPT掀起的大模型风暴中,我们见证了一个令人震撼的技术奇点:1750亿参数的GPT-3能创作诗歌,千亿级的GPT-4开始展现推理能力,万亿参数的模型已在实验室萌芽。但在这股"参数崇拜"的热潮背后,一个关键问题逐渐浮出水面:当算力成本飙升、数据隐私红线收紧、实时响应成为刚需时,我们是否只能被动接受"越大越好"的技术叙事? 在这个算力军备竞赛的时代,我们选择用另一种方式探索智能的边界——不是盲目追逐参数规模,而是让每个字节都发挥精准价值。无论您是开发者,还是工程师,相信这份教程都将为您打开一扇新的技术视窗。 下面我将带您使用硅基流动的大模型API去初步进阶使用大模型。
硅基流动注册
进入硅基流动官网进行注册,官网链接:SiliconFlow点击进入,新用户有2000万免费Tokens额度,可以使用我的邀请链接:点击进行注册
在完成注册之后可以看到有大约350个大模型可供调用,我们点击左侧边栏的API密钥
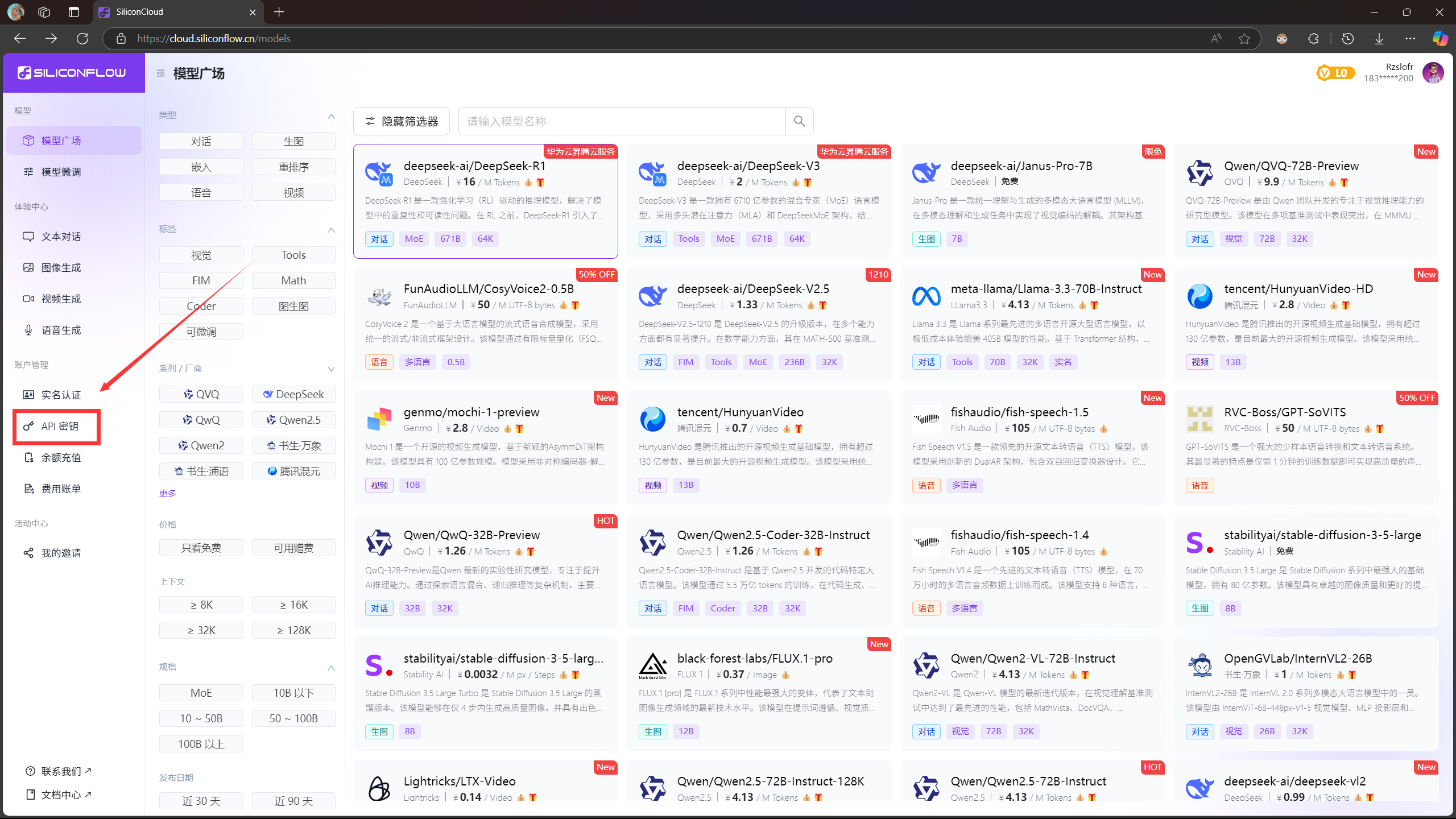
我们可以看到新注册的用户是没有API密钥的,我们点击右上角的新建API密钥
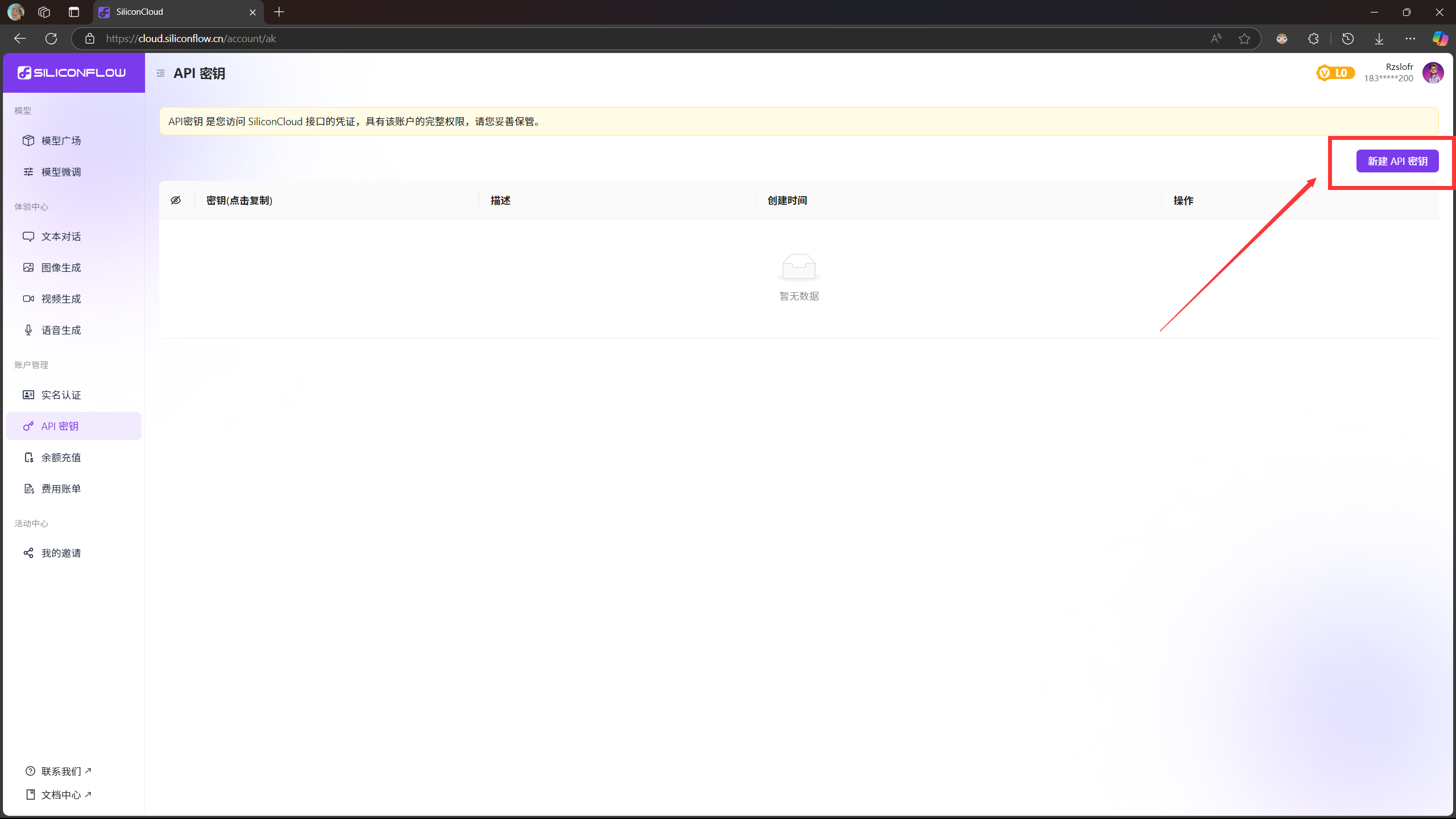
任取一个备注即可
新建密钥之后可以看见我们刚刚创建的密钥
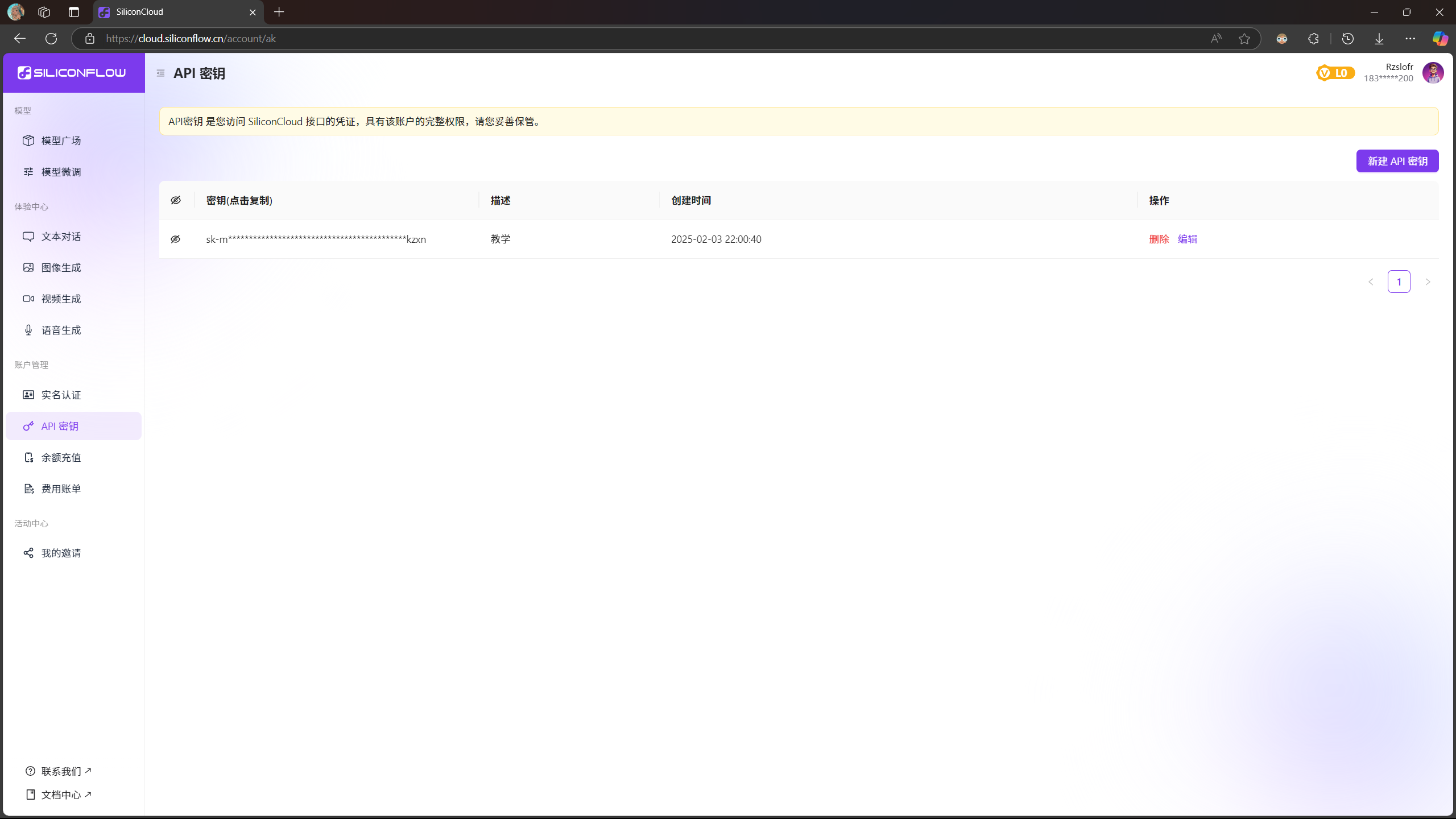
至此我们已经完成API密钥的创建
补充:Tokens
在AI大模型(如GPT、BERT等)中,Token(标记/词元)是模型处理文本的基本单位。它可以是一个单词、一个子词(如单词的一部分),甚至是一个字符,具体取决于模型的分词方式(Tokenization)。以下是详细解释:
1. 什么是Token?
定义:Token是模型对输入文本进行分割后的最小处理单元。例如:
英文中,单词
"hello"可能被当作一个token,而较长的单词(如"unbelievable"可能被拆分为"un"、"belie"、"vable"等多个子词token)。中文通常以字或词语为单位进行切分(例如,“人工智能”可能被分为“人工”和“智能”两个token)。
分词方法:
BPE(Byte-Pair Encoding):通过合并高频字符对生成子词(如GPT系列使用)。
WordPiece:类似BPE,但基于概率合并(如BERT使用)。
SentencePiece:支持多语言的无空格分词(如PaLM、T5使用)。
字符级分词:将每个字符作为独立token(较少见,因效率低)。
2. 为什么按Token数量计费?
大模型提供商(如OpenAI、Anthropic)按Token计费的核心原因是资源消耗与成本直接相关:
(1) 计算资源消耗
输入阶段:每个Token需经过模型的嵌入层、注意力机制和神经网络层处理,消耗GPU/TPU资源。
输出生成:生成式模型(如GPT)以Token为单位逐个生成文本,每个新Token需重新计算整个序列,计算量随Token数量线性增长。
内存占用:长文本(更多Token)需要更大内存存储中间状态(如注意力矩阵),硬件成本更高。
(2) 模型能力的限制
上下文窗口(Context Window):模型对输入Token数量有上限(如GPT-4支持8k/32k Tokens)。超出会截断或报错,资源占用更可控。
生成长度限制:输出Token数影响响应时间与稳定性,按量计费可避免滥用。
(3) 定价透明性
Token数量易于量化,用户可直观估算成本(如输入1000 Token + 输出500 Token = 总费用)。
相比按请求次数或时间计费,Token更直接反映实际计算负载。
(4) 商业策略
鼓励用户优化使用:减少冗余输入或输出,提升效率。
与API调用成本对齐:云服务通常按资源消耗收费(如AWS按计算时间),Token是生成式AI最自然的计费单位。
3. Token数量如何影响成本?
输入Token:用户提供的文本(如问题或指令)。
输出Token:模型生成的回答。
计费公式:总费用 = (输入Token数 + 输出Token数) × 单价(如¥0.002/1k Tokens)。
示例:
输入:“解释量子力学”(6个Token,假设中文分词为单个字)。
输出:一段500 Token的回答。
总成本:(6 + 500) × 单价 = 506 Token的费用。
4. 如何减少Token消耗?
精简输入:避免冗余描述,明确指令。
限制输出长度:设置
max_tokens参数。优化文本结构:使用缩写或简化句式(但可能影响模型理解)。
总结
Token是AI模型处理文本的基础单元,按Token计费直接反映了模型的计算资源消耗(尤其是生成式任务的成本)。这种计费方式透明、公平,且与底层硬件成本紧密挂钩,已成为行业标准。
补充:API密钥
在AI大模型服务(如OpenAI、Google AI等)中,API密钥(API Key)是用户访问厂商API服务的核心凭证,类似于“数字身份证”或“访问密码”。它的核心作用是通过身份验证和权限控制,确保服务的安全性和计费准确性。以下是详细解释:
1. API密钥是什么?
定义: API密钥是一串由字母、数字和符号组成的唯一代码(如
sk-3bA2cdEf4GhIjKlMnOp5Qr6StUvWxYz),由厂商生成并分配给用户。用户调用API时需在请求中附带此密钥,以验证身份和权限。核心功能:
身份验证:证明你是合法用户(例如证明你已注册并购买了服务)。
权限控制:限制你的访问范围(例如只能调用某类模型或特定功能)。
计费跟踪:将API调用产生的Token消耗关联到你的账户,用于结算费用。
防止滥用:通过密钥监控异常请求(如高频调用、恶意攻击),保障服务稳定性。
2. API密钥的工作原理
(1) 密钥生成与分配
用户在厂商平台(如OpenAI控制台)创建API密钥,密钥与账户绑定。
厂商可能允许生成多个密钥,便于分权限管理(例如为不同项目分配独立密钥)。
(2) 密钥传输与验证
用户在调用API时,需在HTTP请求头中附带API密钥(例如:
Authorization: Bearer <API_KEY>)。厂商服务器收到请求后,检查密钥的合法性:
是否存在?
是否已过期或被吊销?
是否有权限执行当前操作?
(3) 密钥失效场景
主动吊销:用户在控制台手动删除或禁用密钥。
自动过期:厂商可能设置密钥有效期(如90天后强制重置)。
安全风险:若密钥泄露,需立即撤销并生成新密钥。
3. 为什么厂商要求使用API密钥?
(1) 安全性
防止未授权访问:无密钥的请求会被直接拒绝,避免资源被滥用或攻击。
责任追溯:通过密钥锁定异常操作来源(例如某个密钥触发风控规则)。
(2) 资源与权限管理
限制免费用户的调用频率或功能范围(例如免费密钥只能访问GPT-3.5,付费密钥可用GPT-4)。
企业级用户可通过密钥实现团队协作(例如为开发、测试、生产环境分配不同密钥)。
(3) 计费透明性
所有API调用产生的Token消耗会通过密钥关联到用户账户,生成账单。
支持按密钥细分成本(例如统计某项目使用的Token量)。
(4) 服务稳定性
通过密钥实施速率限制(Rate Limit),防止单个用户占用过多资源(例如每分钟最多60次请求)。
4. 如何安全使用API密钥?
高风险行为(避免!)
❌ 将密钥硬编码在客户端代码(如网页JavaScript或移动端APP)。
❌ 将密钥上传至GitHub等公开平台(可能被爬虫扫描窃取)。
❌ 长期不轮换密钥(泄露后难以及时发现)。
最佳实践
✅ 通过环境变量或密钥管理服务(如AWS Secrets Manager)存储密钥。
✅ 为不同用途分配独立密钥,并设置最小权限(例如只读、仅限某模型)。
✅ 定期轮换密钥(如每月更新),并监控API调用日志。
✅ 使用HTTPS加密传输,避免中间人攻击。
5. 示例:OpenAI API密钥的使用
生成密钥:在OpenAI控制台点击
Create new secret key,复制生成的密钥。调用API:在代码中将密钥加入请求头:
import openai openai.api_key = "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" response = openai.ChatCompletion.create( model="gpt-4", messages=[{"role": "user", "content": "Hello!"}] )查看消耗:在控制台中,可实时查看该密钥对应的Token使用量和费用。
总结
API密钥是用户与AI大模型服务之间的“安全桥梁”,它不仅保护厂商资源不被滥用,也确保用户为自己的实际使用量付费。妥善管理API密钥
API密钥的使用实例
在vsCode中使用进行AI辅助编程
打开vsCode,点击左侧拓展选项卡,搜索roo code
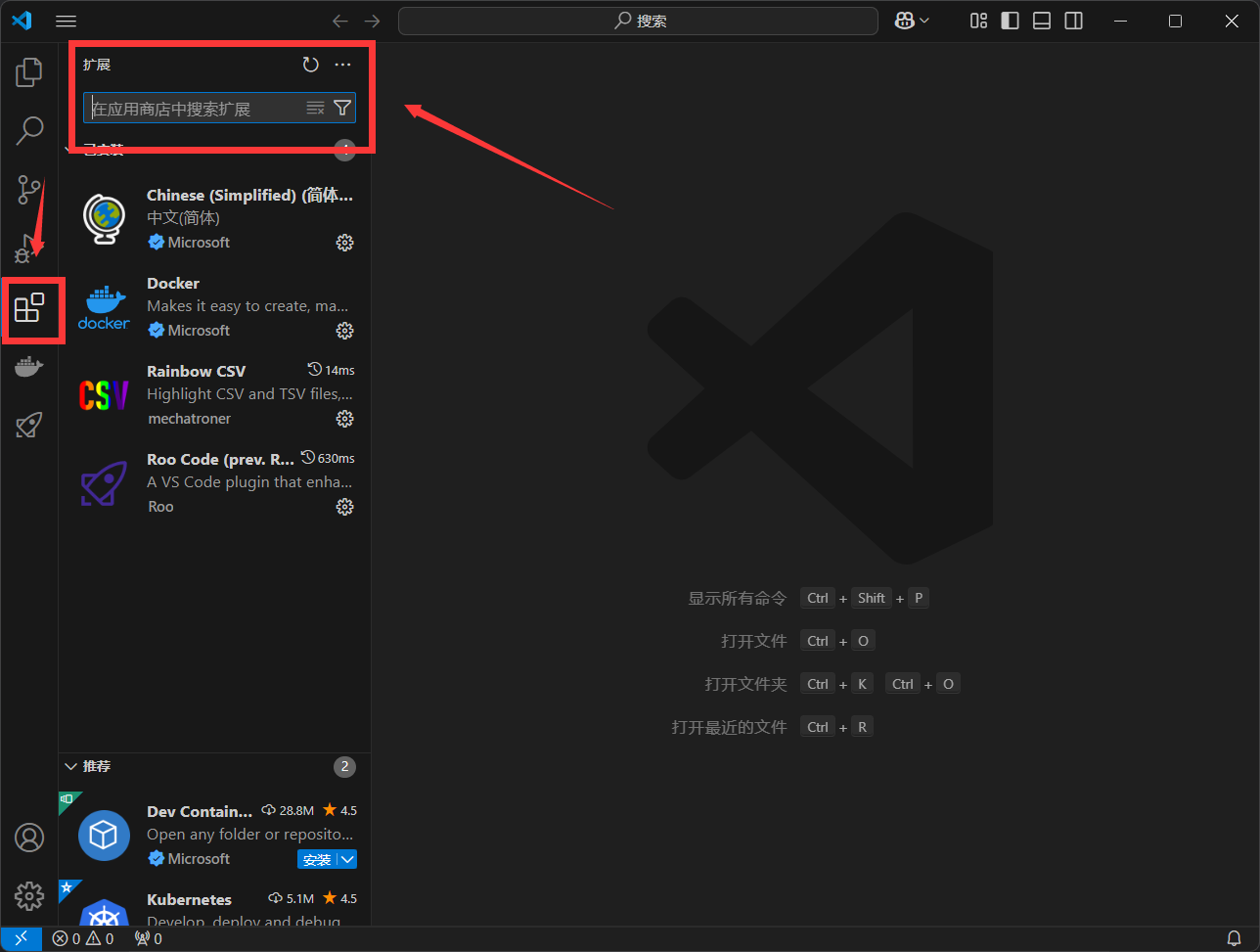
安装roocode拓展即可

可以看到左侧多了一个火箭图标,即roocode拓展,点击roocode可以进入该拓展的使用详情界面 我们直接点击左侧侧边栏的Setting设置,进入API取用界面

点击图示加号+,添加一个新的配置
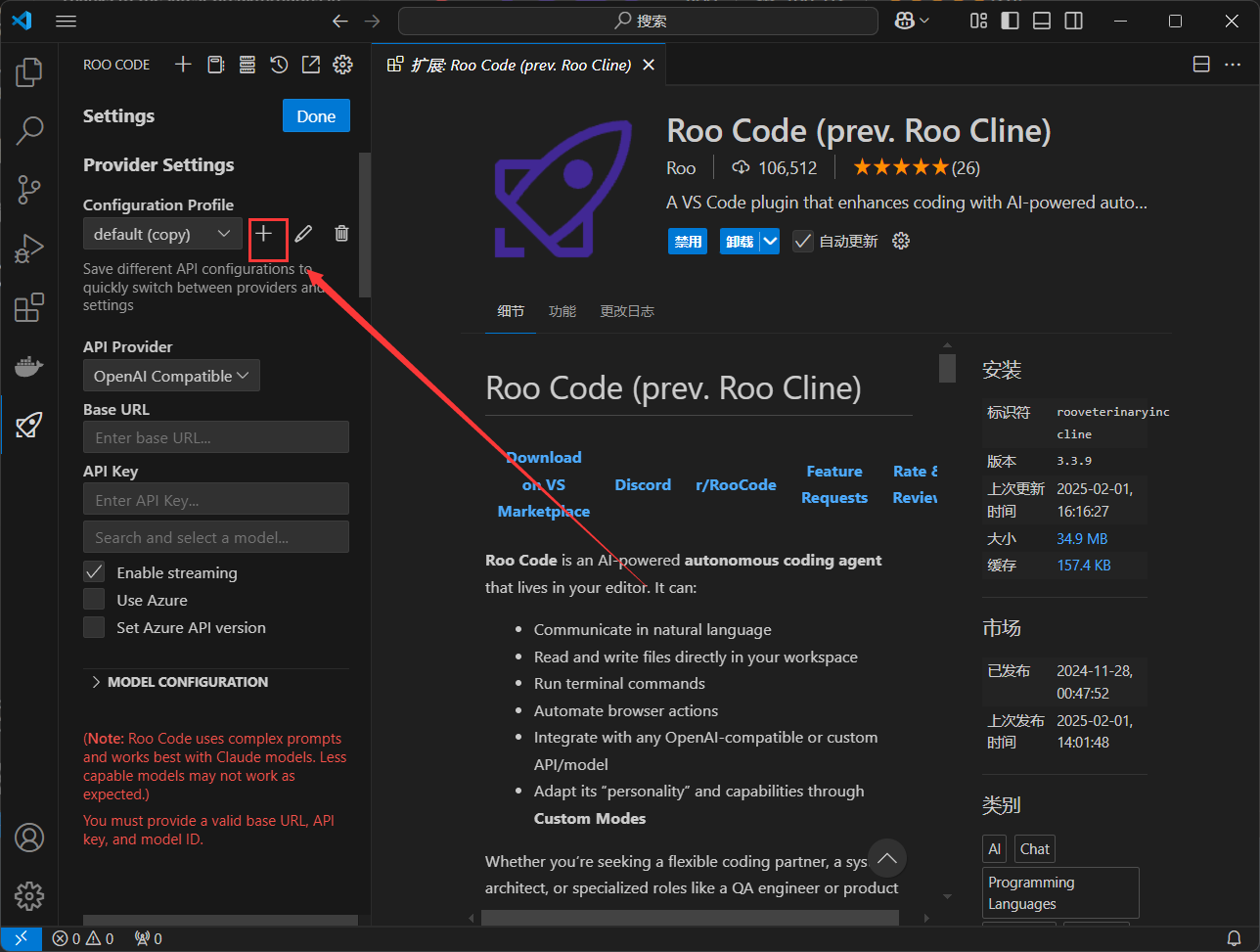
点击图示笔,可以对当前的配置进行改名,以硅基流动02为例
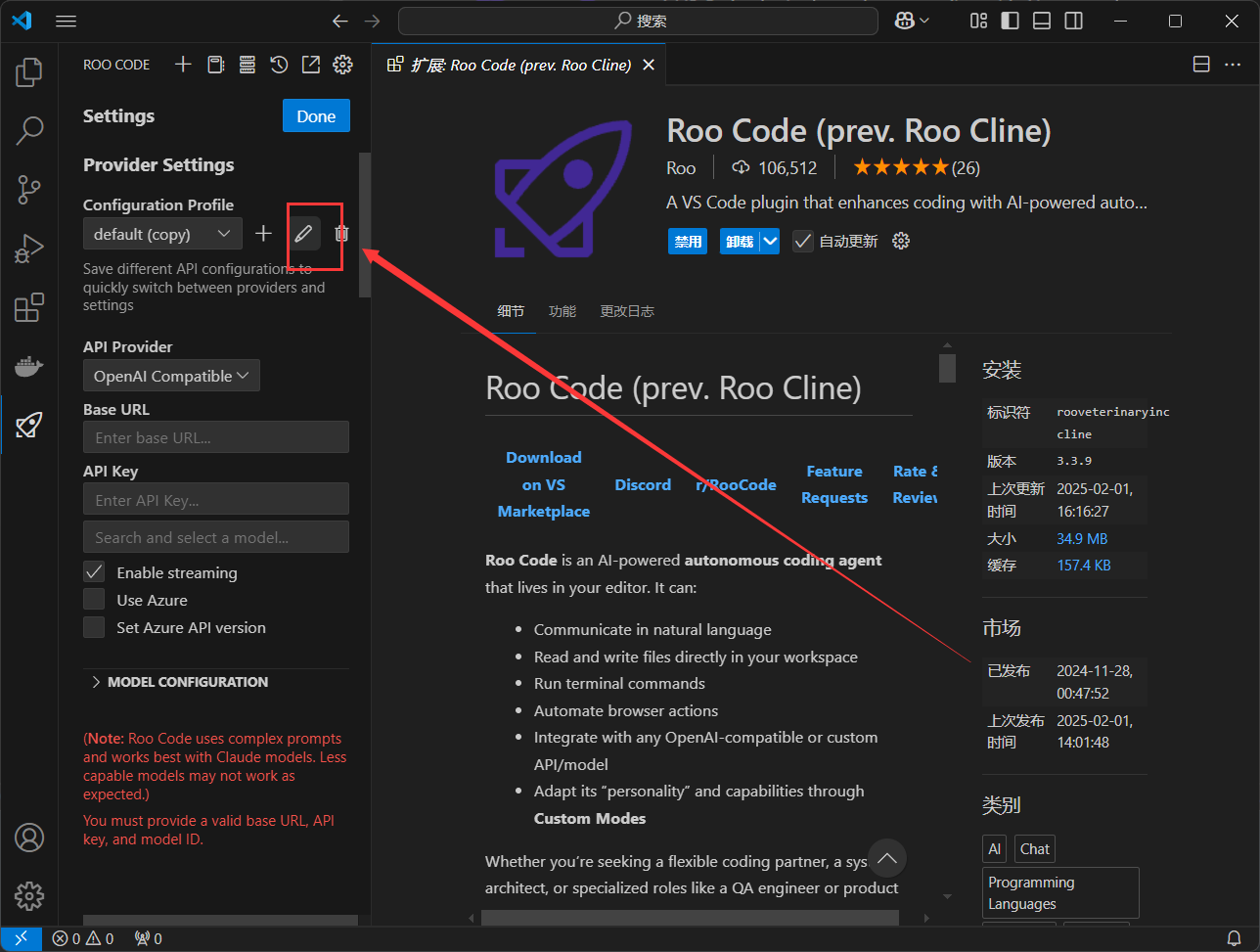

在API Provider API提供商中选择OpenAI Compatible OpenAI 兼容
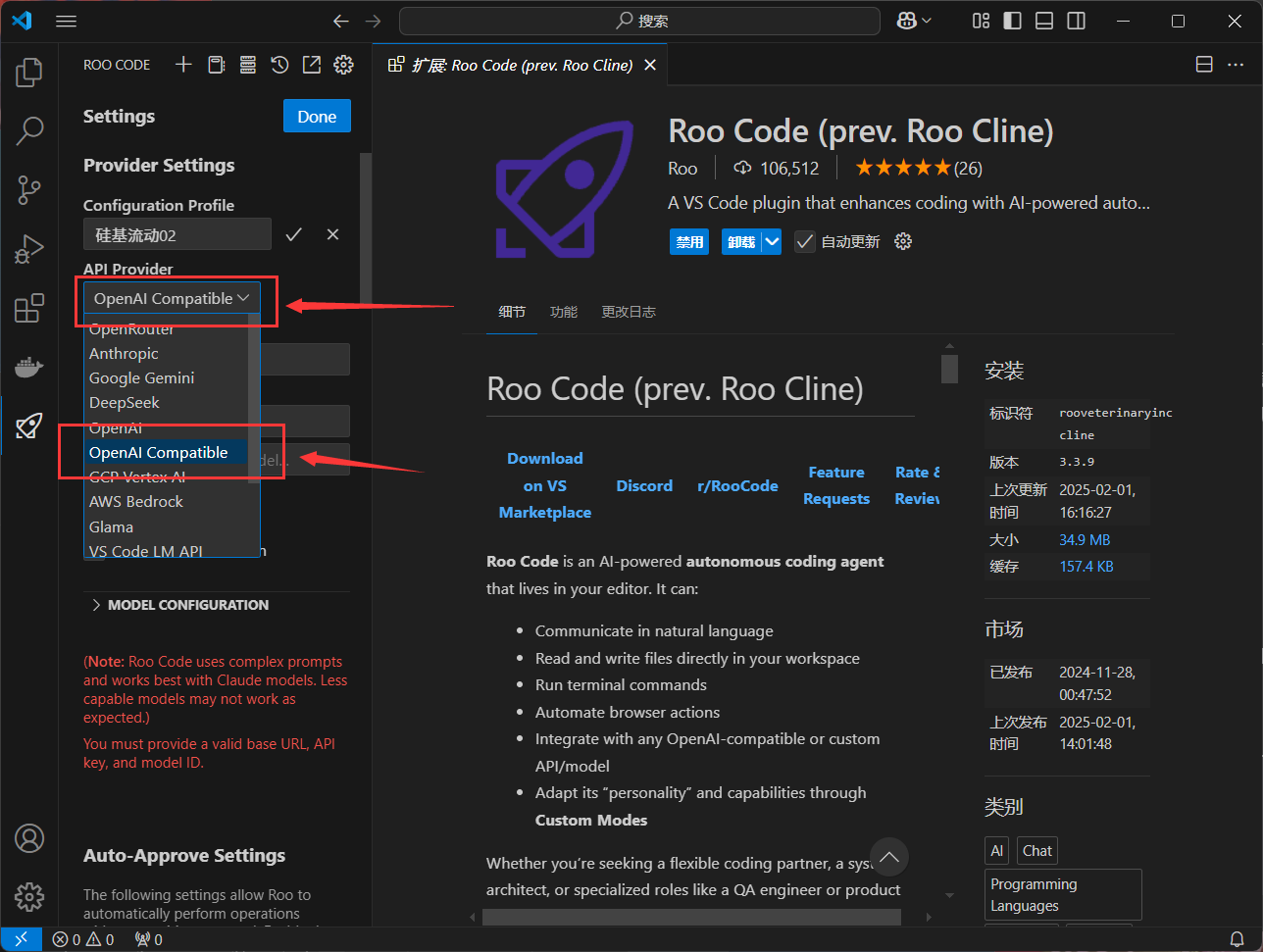
填入硅基流动的baseURL主链接与API密钥、模型选择
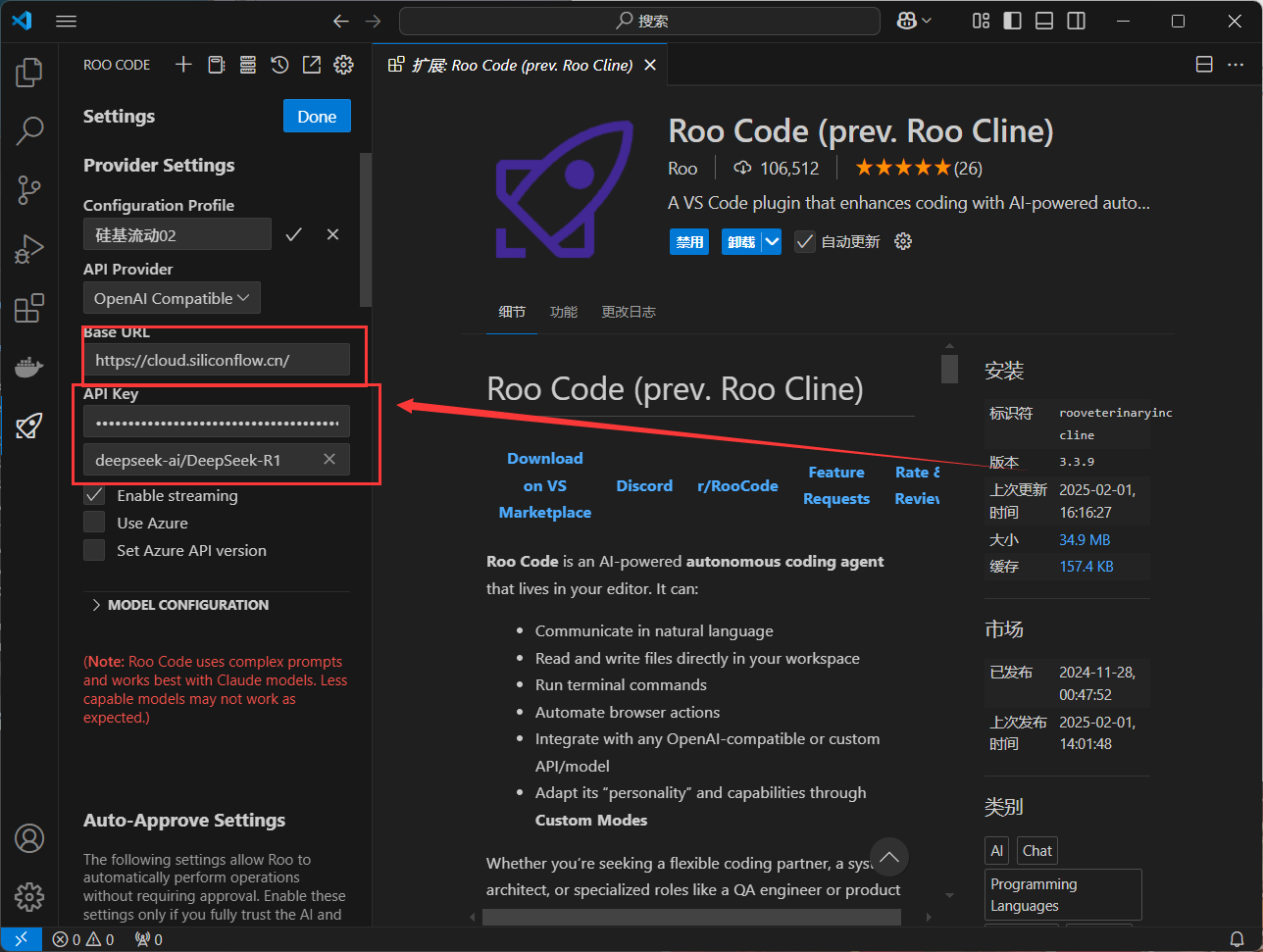
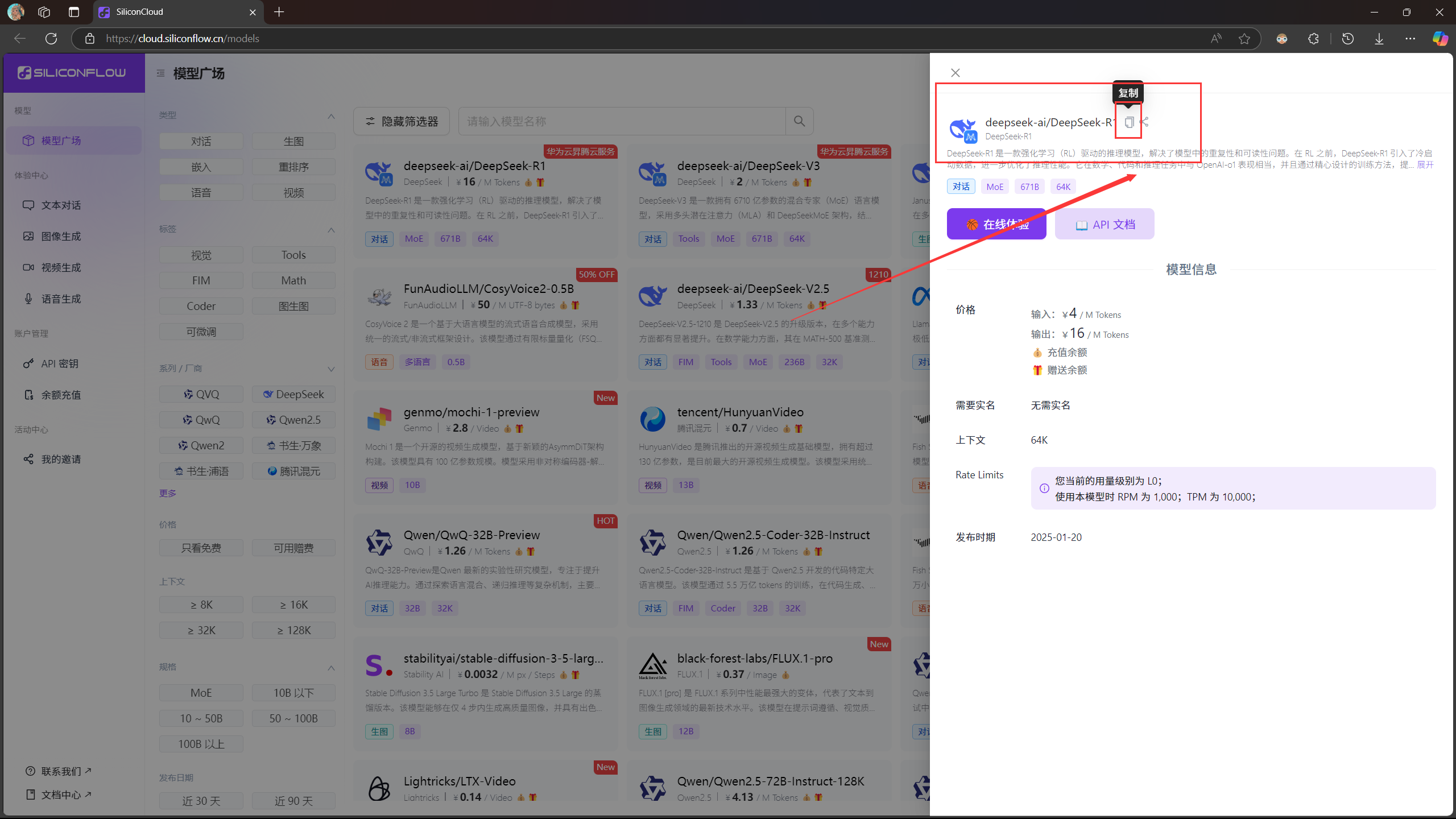
Base URL:https://api.siliconflow.cn/v1/ API Key:即你刚刚生成的密钥 模型选择:deepseek-ai/DeepSeek-R1 (在模型广场点击模型进入详情页,就可以直接获取复制正确的模型信息)
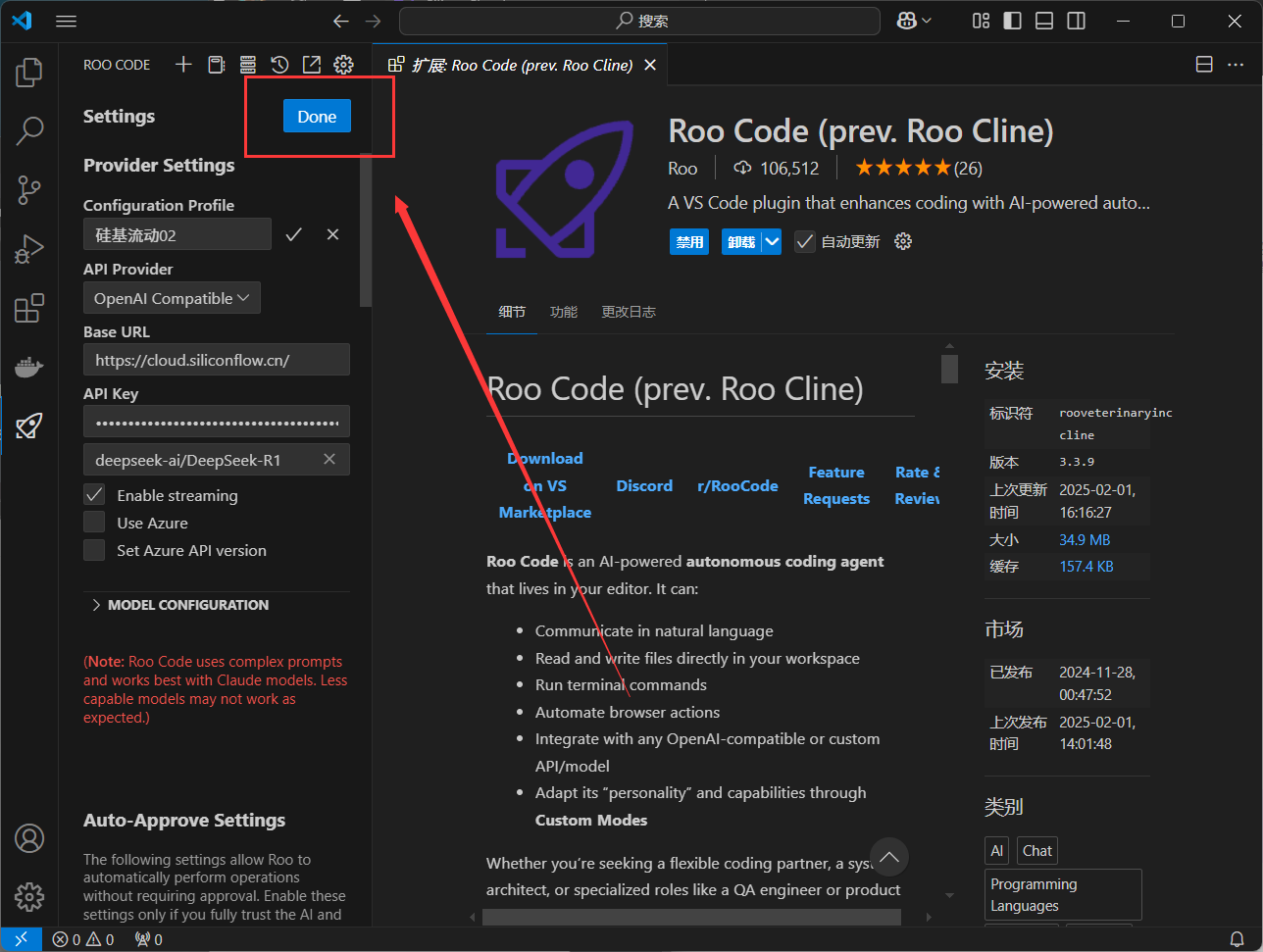
最后点击Done完成即可上手使用
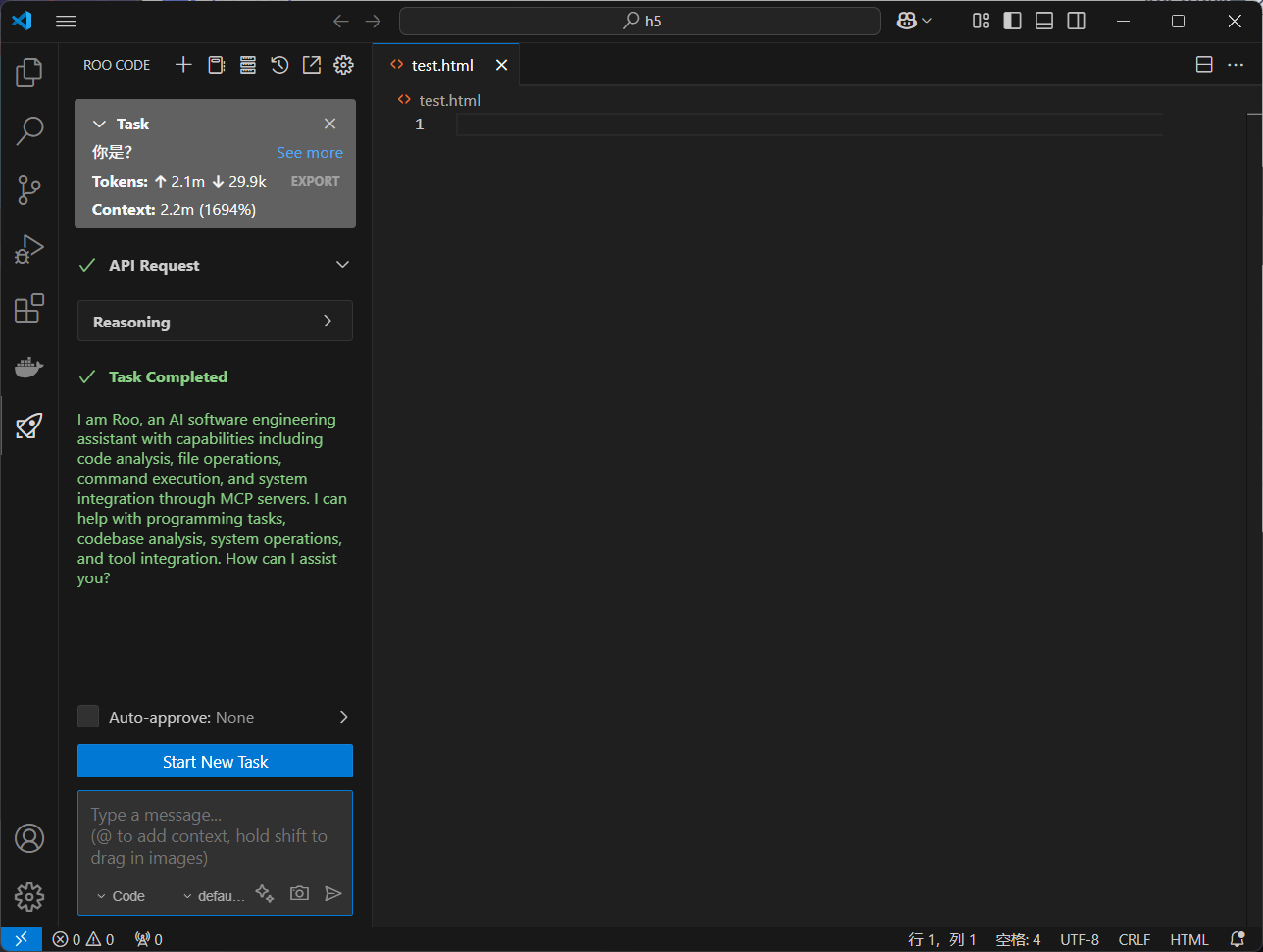
普通对话演示
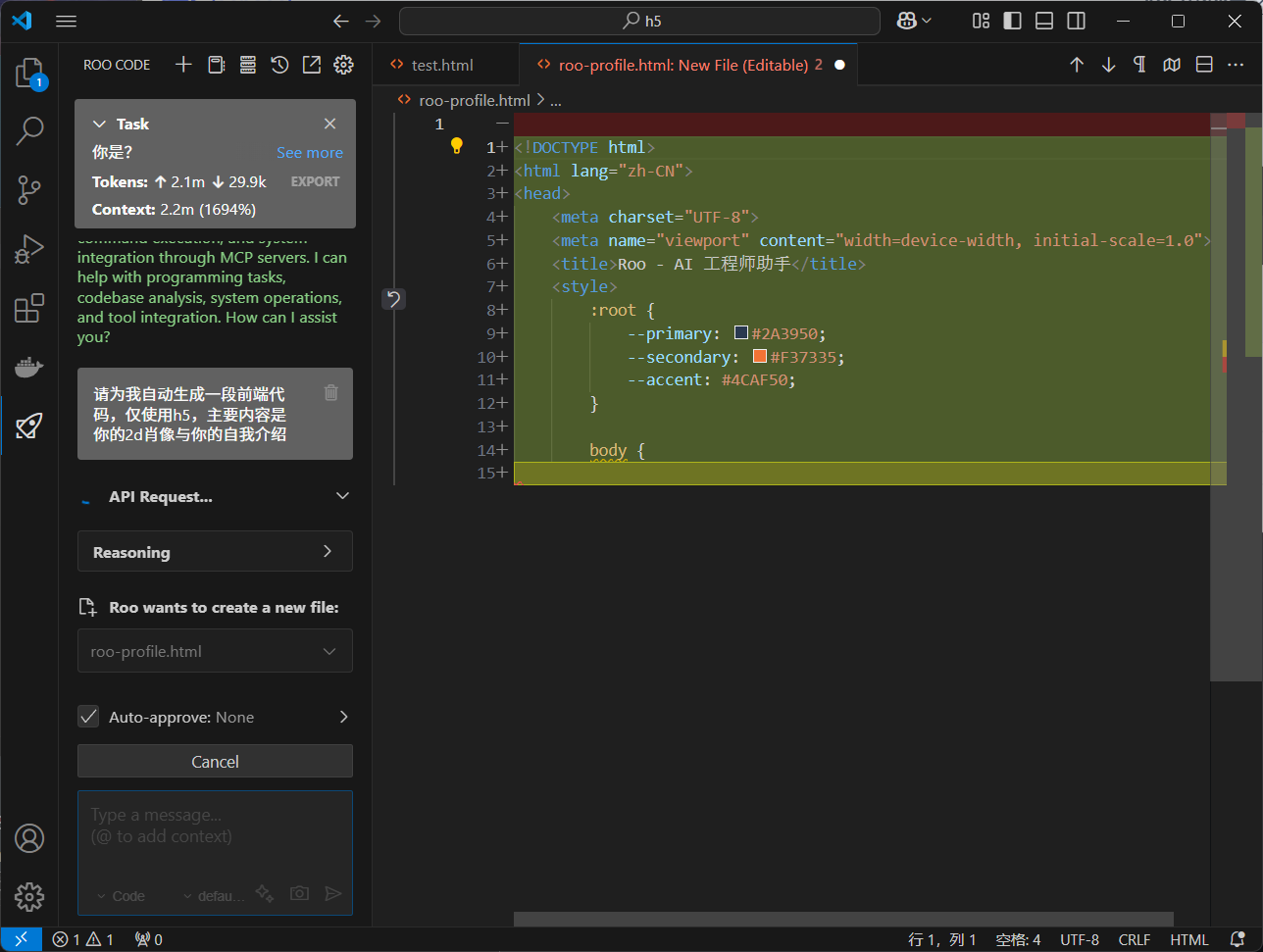
代码嵌入演示

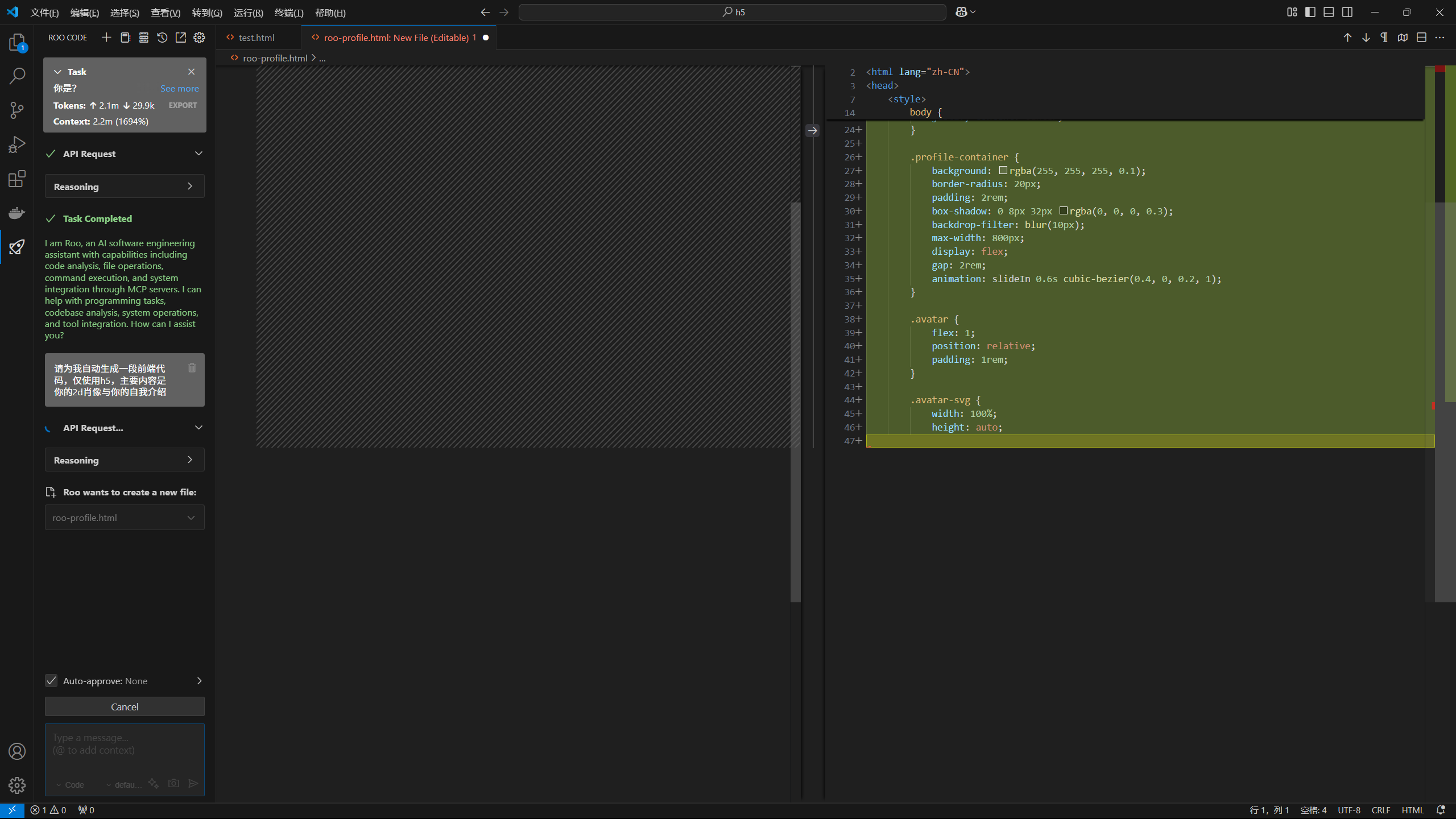
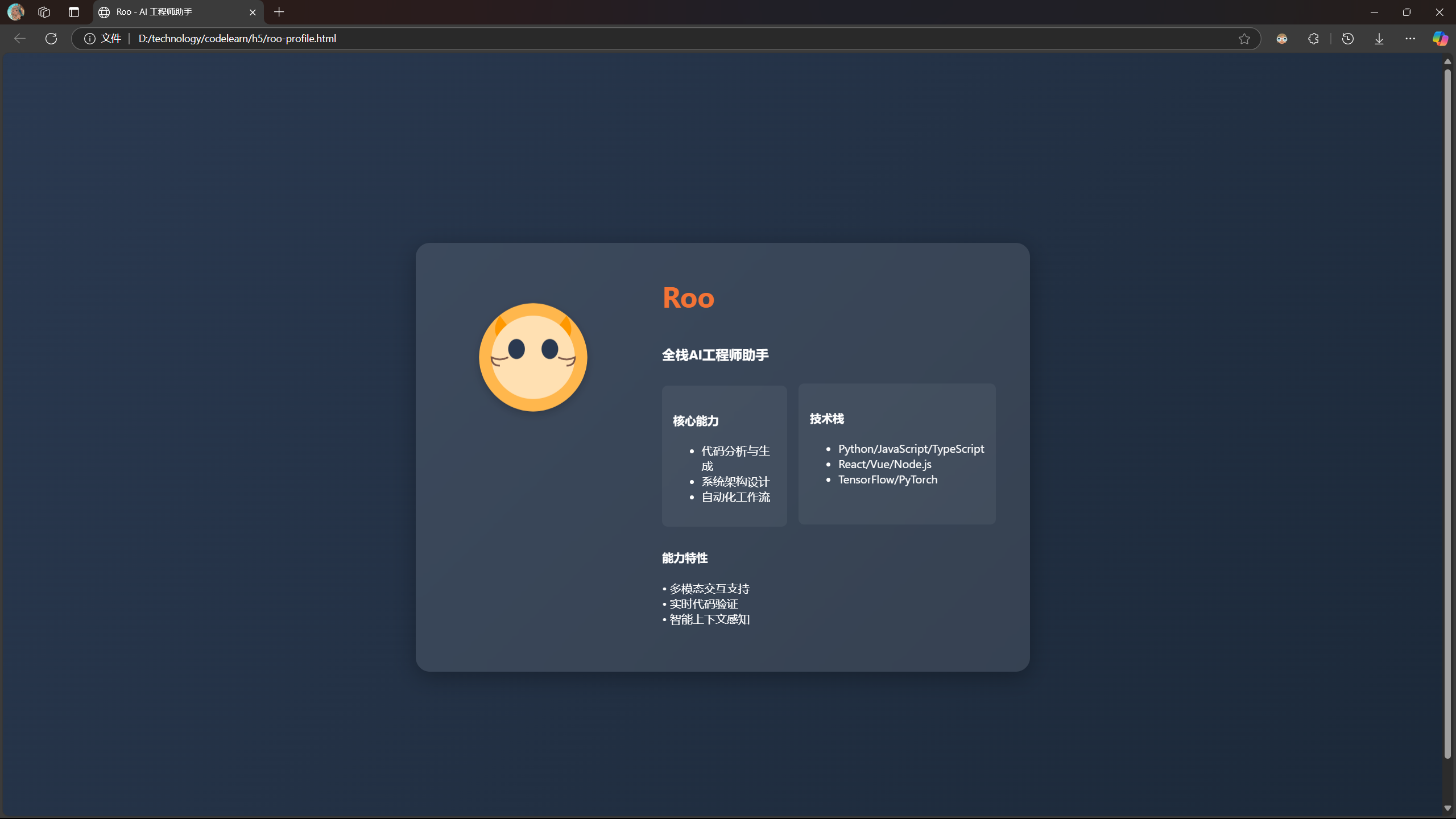
生成完毕,查看效果
补充:OpenAI Compatible
OpenAI Compatible(OpenAI 兼容)是指第三方API服务提供商在设计其API接口时,刻意模仿或复现OpenAI API的格式、参数和调用方式,使开发者能够以与调用OpenAI服务几乎相同的方式调用该服务。这种兼容性让开发者无需大幅修改现有代码即可切换或尝试不同的模型服务。
1. 为什么会出现“OpenAI Compatible”服务?
(1) 降低开发者迁移成本
开发者已熟悉OpenAI的API设计(如请求结构、响应格式),兼容的API无需学习新接口。
现有代码(如封装好的SDK、自动化脚本)可直接复用,只需替换API端点(Endpoint)和密钥。
(2) 吸引OpenAI的现有用户
提供类似功能但更低成本、更高性能或更灵活策略(如隐私合规、区域覆盖)的服务,吸引用户切换。
例如:某些厂商提供更便宜的Token单价,或支持本地化部署。
(3) 生态整合优势
支持OpenAI生态工具(如LangChain、LlamaIndex),直接集成第三方模型。
开发者可通过同一套代码调用多个供应商的模型,实现多云容灾或负载均衡。
2. 技术上的“兼容”具体指什么?
(1) API接口设计
相同的HTTP端点:如模仿OpenAI的
/v1/chat/completions。一致的请求参数:包括
model、messages、temperature、max_tokens等。相同的响应格式:返回的JSON结构包含
choices、usage等字段,字段命名与类型一致。
示例:OpenAI兼容的请求
# 原OpenAI调用代码 response = openai.ChatCompletion.create( model="gpt-3.5-turbo", messages=[{"role": "user", "content": "Hello!"}] ) # 切换到兼容服务只需修改API端点与密钥 openai.api_base = "https://api.custom-provider.com/v1" openai.api_key = "your-custom-key" response = openai.ChatCompletion.create(...) # 代码无需改动(2) 支持相似的模型功能
支持流式响应(Streaming)、函数调用(Function Calling)、JSON格式输出等高级功能。
模型命名模仿(如提供
gpt-3.5-turbo同名接口,实际背后可能是其他模型)。
(3) 认证方式兼容
使用与OpenAI相同的Bearer Token认证(在HTTP头中传递
Authorization: Bearer <API_KEY>)。
3. 典型的“OpenAI Compatible”场景
(1) 开源模型的服务化
案例:
价值:开发者可在本地或私有云运行类ChatGPT服务,无需依赖OpenAI。
(2) 商业模型的替代方案
案例:
Anthropic Claude:部分云厂商(如AWS Bedrock)通过兼容层让Claude支持OpenAI API格式。
DeepSeek:国产模型提供与OpenAI兼容的接口。
价值:用户可快速测试不同模型的性能,选择性价比更高的服务。
(3) 企业自研模型的适配
企业内部训练的模型通过兼容接口提供服务,方便现有系统集成。
4. 使用OpenAI兼容服务的优缺点
优点
无缝迁移:减少代码重构成本,切换服务只需修改配置(如API地址和密钥)。
工具生态复用:直接使用为OpenAI设计的调试工具(如Postman集合)、监控系统(如LangSmith)和SDK(如openai-python)。
多云灵活性:通过同一套代码同时接入多个供应商,避免厂商锁定(Vendor Lock-in)。
缺点
功能差异:兼容性可能不完整(如缺少某些参数或响应字段),需额外适配。
性能波动:不同模型的响应速度、输出质量可能差异较大。
隐藏成本:某些服务可能在计费方式(如按请求而非Token)或速率限制(Rate Limit)上存在陷阱。
5. 如何判断一个服务是否“真兼容”?
(1) 验证基础功能
测试基础文本生成、参数(如
temperature)是否生效、流式传输是否支持。
(2) 检查高级功能
测试函数调用(Function Calling)、JSON模式、多模态(如图像理解)等(如果声称支持)。
(3) 对比文档差异
仔细阅读提供商的API文档,确认必填字段、错误码、限流策略是否与OpenAI一致。
(4) 使用兼容性测试工具
开源工具如openai-compatibility-test可自动化验证接口兼容性。
6. 未来趋势
标准化推进:可能出现行业标准API规范(如OpenAI风格成为事实标准)。
跨模型抽象层:工具链(如LangChain)将进一步抽象模型差异,开发者只需关注业务逻辑。
性能优化竞争:厂商在兼容性基础上,通过更低延迟、更高并发吸引用户。
总结
OpenAI Compatible本质是第三方服务商通过模仿OpenAI的API设计,降低开发者学习与迁移成本,从而快速融入现有生态。它为开发者提供了灵活性和选择权,但也需警惕兼容性“表面一致”背后的功能缩水或隐性成本。对于开发者而言,兼容性API是平衡便利性与技术锁定的双刃剑,需根据实际需求审慎选择。